不归一化层的Transformer!刘壮带队,何恺明、Ya
栏目:行业新闻 发布时间:2025-03-15 09:30
何恺明又双叒叕发新作了,此次仍是与图灵奖得主 Yann LeCun 配合。这项研讨的主题是不归一化层的 Transformer(Transformers without Normalization),并已被 CVPR 2025 集会接受。 从前十年,归一化层曾经坚固了其作为古代神经收集最基础组件之一的位置。这所有能够追溯到 2015 年批归一化(batch normalization)的发现,它使视觉辨认模子的收敛速率变得更快、更好,并在随后多少年中取得敏捷开展。从当时起,研讨职员针对差别的收集架构或范畴提出了很多归一化层的变体。现在,多少乎全部古代收集都在应用归一化层,此中层归一化(Layer Norm,LN)是最受欢送之一,特殊是在占主导位置的 Transformer 架构中。归一化层的普遍利用很年夜水平上得益于它们在优化方面的实证上风。除了实现更好的成果之外,归一化层另有助于减速跟稳固收敛。跟着神经收集变得越来越宽、越来越深,归一化层的须要性变得越来越主要。因而,研讨职员广泛以为归一化层对无效练习深度收集至关主要,乃至是必弗成少的。这一观念现实上失掉了奥妙证实:比年来,新架构常常追求代替留神力层或卷积层,但多少乎老是保存归一化层。本文中,研讨者提出了 Transformer 中归一化层的一种简略平替。他们的摸索始于以下察看:LN 层应用类 tanh 的 S 形曲线将其输入映射到输出,同时缩放输入激活并紧缩极值。受此启示,研讨者提出了一种元素级运算,称为 Dynamic Tanh(DyT),界说为:DyT (x) = tanh (αx),此中 α 是一个可进修参数。此运算旨在经由过程 α 进修恰当的缩放因子并经由过程有界 tanh 函数紧缩极值来模仿 LN 的行动。值得留神的是,与归一化层差别,DyT 能够实现这两种后果,而无需盘算激活数据。论文一作 Jiachen Zhu 为纽约年夜学四年级博士生、二作陈鑫磊(Xinlei Chen)为 FAIR 研讨迷信家,名目担任工资刘壮。
从前十年,归一化层曾经坚固了其作为古代神经收集最基础组件之一的位置。这所有能够追溯到 2015 年批归一化(batch normalization)的发现,它使视觉辨认模子的收敛速率变得更快、更好,并在随后多少年中取得敏捷开展。从当时起,研讨职员针对差别的收集架构或范畴提出了很多归一化层的变体。现在,多少乎全部古代收集都在应用归一化层,此中层归一化(Layer Norm,LN)是最受欢送之一,特殊是在占主导位置的 Transformer 架构中。归一化层的普遍利用很年夜水平上得益于它们在优化方面的实证上风。除了实现更好的成果之外,归一化层另有助于减速跟稳固收敛。跟着神经收集变得越来越宽、越来越深,归一化层的须要性变得越来越主要。因而,研讨职员广泛以为归一化层对无效练习深度收集至关主要,乃至是必弗成少的。这一观念现实上失掉了奥妙证实:比年来,新架构常常追求代替留神力层或卷积层,但多少乎老是保存归一化层。本文中,研讨者提出了 Transformer 中归一化层的一种简略平替。他们的摸索始于以下察看:LN 层应用类 tanh 的 S 形曲线将其输入映射到输出,同时缩放输入激活并紧缩极值。受此启示,研讨者提出了一种元素级运算,称为 Dynamic Tanh(DyT),界说为:DyT (x) = tanh (αx),此中 α 是一个可进修参数。此运算旨在经由过程 α 进修恰当的缩放因子并经由过程有界 tanh 函数紧缩极值来模仿 LN 的行动。值得留神的是,与归一化层差别,DyT 能够实现这两种后果,而无需盘算激活数据。论文一作 Jiachen Zhu 为纽约年夜学四年级博士生、二作陈鑫磊(Xinlei Chen)为 FAIR 研讨迷信家,名目担任工资刘壮。 论文题目:Transformers without Normalization论文地点:https://arxiv.org/pdf/2503.10622名目主页:https://jiachenzhu.github.io/DyT/GitHub 地点:https://github.com/jiachenzhu/DyTDyT 应用起来十分简略,如下图 1 所示,研讨者直接用 DyT 调换视觉跟言语 Transformer 等架构中的现有归一化层。实证成果标明,应用 DyT 的模子能够在种种设置中稳固练习并取得较高的终极机能。同时,DyT 平日不须要在原始架构上调剂练习超参数。
论文题目:Transformers without Normalization论文地点:https://arxiv.org/pdf/2503.10622名目主页:https://jiachenzhu.github.io/DyT/GitHub 地点:https://github.com/jiachenzhu/DyTDyT 应用起来十分简略,如下图 1 所示,研讨者直接用 DyT 调换视觉跟言语 Transformer 等架构中的现有归一化层。实证成果标明,应用 DyT 的模子能够在种种设置中稳固练习并取得较高的终极机能。同时,DyT 平日不须要在原始架构上调剂练习超参数。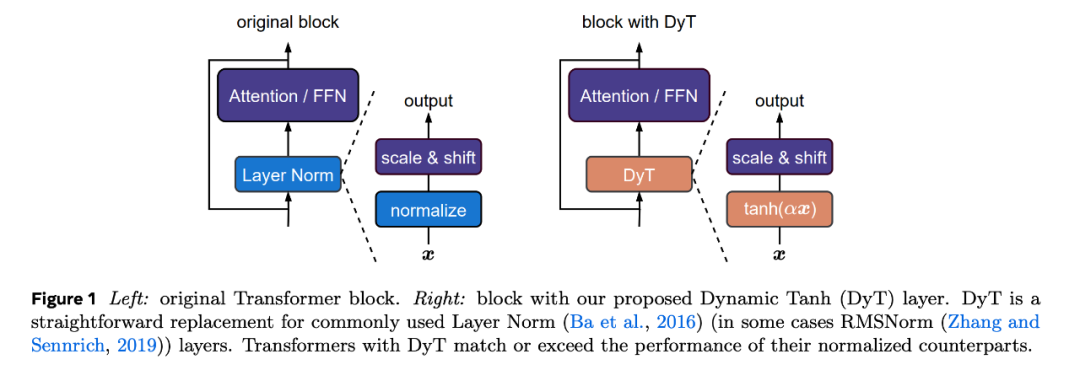 DyT 模块能够经由过程短短多少行 PyTorch 代码来实现。
DyT 模块能够经由过程短短多少行 PyTorch 代码来实现。
从前十年,归一化层曾经坚固了其作为古代神经收集最基础组件之一的位置。这所有能够追溯到 2015 年批归一化(batch normalization)的发现,它使视觉辨认模子的收敛速率变得更快、更好,并在随后多少年中取得敏捷开展。从当时起,研讨职员针对差别的收集架构或范畴提出了很多归一化层的变体。现在,多少乎全部古代收集都在应用归一化层,此中层归一化(Layer Norm,LN)是最受欢送之一,特殊是在占主导位置的 Transformer 架构中。归一化层的普遍利用很年夜水平上得益于它们在优化方面的实证上风。除了实现更好的成果之外,归一化层另有助于减速跟稳固收敛。跟着神经收集变得越来越宽、越来越深,归一化层的须要性变得越来越主要。因而,研讨职员广泛以为归一化层对无效练习深度收集至关主要,乃至是必弗成少的。这一观念现实上失掉了奥妙证实:比年来,新架构常常追求代替留神力层或卷积层,但多少乎老是保存归一化层。本文中,研讨者提出了 Transformer 中归一化层的一种简略平替。他们的摸索始于以下察看:LN 层应用类 tanh 的 S 形曲线将其输入映射到输出,同时缩放输入激活并紧缩极值。受此启示,研讨者提出了一种元素级运算,称为 Dynamic Tanh(DyT),界说为:DyT (x) = tanh (αx),此中 α 是一个可进修参数。此运算旨在经由过程 α 进修恰当的缩放因子并经由过程有界 tanh 函数紧缩极值来模仿 LN 的行动。值得留神的是,与归一化层差别,DyT 能够实现这两种后果,而无需盘算激活数据。论文一作 Jiachen Zhu 为纽约年夜学四年级博士生、二作陈鑫磊(Xinlei Chen)为 FAIR 研讨迷信家,名目担任工资刘壮。论文题目:Transformers without Normalization论文地点:https://arxiv.org/pdf/2503.10622名目主页:https://jiachenzhu.github.io/DyT/GitHub 地点:https://github.com/jiachenzhu/DyTDyT 应用起来十分简略,如下图 1 所示,研讨者直接用 DyT 调换视觉跟言语 Transformer 等架构中的现有归一化层。实证成果标明,应用 DyT 的模子能够在种种设置中稳固练习并取得较高的终极机能。同时,DyT 平日不须要在原始架构上调剂练习超参数。DyT 模块能够经由过程短短多少行 PyTorch 代码来实现。